亮相即惊艳,SuperCLUE测试中讯飞星火排名国内第一!
前有ChatGPT,后有百度文心、阿里千问、京东灵犀,一时间“AI大模型”一词迅速成为了网络流行语。并且在短短几个月时间内,国内有超过30家科技公司入局,彻底拉开了国内人工智能战场的序幕。5月6日,讯飞星火认知大模型成果发布会在安徽合肥举行,现场实测大模型七大核心能力,并发布了汽车、教育、办公、数字员工四大行业应用成果。
同时,讯飞星火认知大模型在应用场景落地方面也有很大突破,比如1+N模式,其中“1”是通用的人工智能底座,“N”是在教育、医疗、办公、人机交互、车载等领域的行业纵深应用,可见讯飞的星火认知大模型准备工作是非常充分的。

那备受瞩目的讯飞星火认知大模型在目前已知的AI大模型相比,实力究竟如何呢?人工智能大模型有没有官方统一的评测标准?就在5月9日,中文通用大模型综合性评测基准 SuperCLUE 正式发布。它主要解决的问题是在当前通用大模型大力发展的情况下,中文大模型的效果情况,包括但不限于这些模型不同任务的效果情况、和国际上代表性模型的比较情况以及和人类对比的效果。一系列国内外代表性模型在该基准下的多个维度接受能力测试,进而得出SuperCLUE评测榜单。

该基准测试主要关注以下问题:中文大模型在不同任务上的表现如何?与国际代表性模型相比,中文大模型的表现达到了何种程度?中文大模型与人类表现相比如何?该模型可通过多个层面,考验市面上主流的中文GPT大模型的能力。其中,基础能力包括了常见的有代表性的模型能力,如语义理解、对话、逻辑推理、角色模拟、代码、生成与创作等10项能力。专业能力包括了中学、大学与专业考试,涵盖了从数学、物理、地理到社会科学等50多项能力。中文特性能力,针对有中文特点的任务,包括了中文成语、诗歌、文学、字形等10项多种能力。
除了多维度考察,SuperCLUE评测榜单还拥有自动化评测、广泛代表性和采取人类基准等特点,较为客观、全面展现当下的通用大模型的能力。
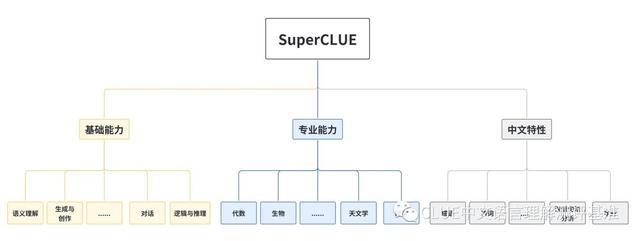
该机构利用 SuperCLUE 测试基准,对市面上主流的支持中文的通用大模型进行了评测与排名。从排名中我们可以看出,GPT-4 一骑绝尘,已经非常接近人类的能力。国产大模型中讯飞科技研发的星火认知大模型总排名第三,国内排名第一。
多年来,科大讯飞已在认知智能领域有了丰富的储备和积累,此次成果发布,科大讯飞开放合作,与广大合作伙伴共建人工智能“星火”生态,为更多行业赋能,推动发展。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
关键词:
相关推荐
-
 聚力四大核心版块,卓越集团打造完善的“城市综合运
聚力四大核心版块,卓越集团打造完善的“城市综合运 -
 瑞浦兰钧发布续航数据,问顶158Ah电池会是新能源车
瑞浦兰钧发布续航数据,问顶158Ah电池会是新能源车 -
 兴长信达:自建MCN机构,打造全生态直播产业链
兴长信达:自建MCN机构,打造全生态直播产业链 -
 智能电池合资项目启动,一汽解放加速新能源转型
智能电池合资项目启动,一汽解放加速新能源转型 -
 阿里云发布创业者计划:支持30000家创业公司,每家
阿里云发布创业者计划:支持30000家创业公司,每家 -
 平安产险北京分公司保障先行抢险救灾 为生命财产安
平安产险北京分公司保障先行抢险救灾 为生命财产安 -
 康姿百德床垫,打造年轻人健康舒适的睡眠体验
康姿百德床垫,打造年轻人健康舒适的睡眠体验 -
 2023(南京)创新材料产业研讨峰会成功举办
2023(南京)创新材料产业研讨峰会成功举办 -
 Sandalwood Advisors受邀出席2023第30届CITIC CLS
Sandalwood Advisors受邀出席2023第30届CITIC CLS -
 哪个品牌的有机奶粉营养好?法版优博营养丰富品质保
哪个品牌的有机奶粉营养好?法版优博营养丰富品质保 -
 2023 IDC中国未来企业大奖公布,多家亚马逊云科技
2023 IDC中国未来企业大奖公布,多家亚马逊云科技 -
 解决英语学习难题?讯飞AI翻译笔P20 Plus给你想要
解决英语学习难题?讯飞AI翻译笔P20 Plus给你想要 -
 国际模特大赛落地 潮奢品牌深度链接 武汉百联奥莱
国际模特大赛落地 潮奢品牌深度链接 武汉百联奥莱 -
 实力出圈,伊顿全新 BZM 塑壳断路器专为 OEM 行业定制
实力出圈,伊顿全新 BZM 塑壳断路器专为 OEM 行业定制 -
 成都农商银行总行营业部获评“第21届全国青年文明号
成都农商银行总行营业部获评“第21届全国青年文明号 -
 杭州灵伴科技实力引领,省经信厅领导调研体验元宇宙
杭州灵伴科技实力引领,省经信厅领导调研体验元宇宙
热点图集
- 聚力四大核心版块,卓越集团打造完善的“城市综合运
-
 集火成炬 群星闪耀丨升阳光开启全国招商新征程
集火成炬 群星闪耀丨升阳光开启全国招商新征程 - 瑞浦兰钧发布续航数据,问顶158Ah电池会是新能源车
- 智能电池合资项目启动,一汽解放加速新能源转型
- 兴长信达:自建MCN机构,打造全生态直播产业链
- 阿里云发布创业者计划:支持30000家创业公司,每家
- 平安产险北京分公司保障先行抢险救灾 为生命财产安
- 康姿百德床垫,打造年轻人健康舒适的睡眠体验
- 2023(南京)创新材料产业研讨峰会成功举办
- Sandalwood Advisors受邀出席2023第30届CITIC CLS
- 哪个品牌的有机奶粉营养好?法版优博营养丰富品质保
- 2023 IDC中国未来企业大奖公布,多家亚马逊云科技
- 解决英语学习难题?讯飞AI翻译笔P20 Plus给你想要
- 国际模特大赛落地 潮奢品牌深度链接 武汉百联奥莱
- 实力出圈,伊顿全新 BZM 塑壳断路器专为 OEM 行业定制
- 成都农商银行总行营业部获评“第21届全国青年文明号